VMware hat mit vSphere 6.0 das Feature Content Library eingeführt, das es Unternehmen mit verteilten Standorten ermöglicht, VM-Vorlagen, ISOs, OVF/OVAs und vApp konsistent zu halten. Seitdem wurden die Funktionen von Content Libraries weiter ausgebaut, so dass sie nun auch für kleine Firmen von Nutzen sind.
In der Praxis werden vSphere-Administratoren virtuelle Maschinen nur selten von Grund auf neu installieren. Gängige Methoden zur Automatisierung der Bereitstellung sind VM-Vorlagen, OVA/OVFs und vApps. Sollen oder müssen trotzdem VMs komplett neu erzeugt werden, dann ist es sinnvoll, auch ISOs an einem zentralen Speicherort zu pflegen.
Vor vSphere 6.0 dienten in der Regel Datastores als Speicherort. Verfügen Unternehmen über mehrere Standorte mit jeweils eigener Storage-Infrastruktur und verknüpften vCentern, dann garantiert ein Speicher-Backend allein aber noch keine konsistente Datenhaltung. Außerdem ist die mehrfache Speicherung an unterschiedlichen Standorten nicht sonderlich effizient.
Konzept von Content Libraries
Bei Content Libraries spielen die drei Aspekte Sharing/Consistency, Storage Effciency und Secure Subscription eine wichtige Rolle.
Die Idee dabei: Physisch speichert jeder Standort die Vorlagenelemente lokal in seinem Storage-Backend, sprich einem Datastore-Objekt. Logisch hingegen werden die Objekte an einem zentralen „Ort“, dem Content-Library-Objekt abgelegt. Allerdings hat jeder Standort ein eigenes Content-Library-Objekt in seinem vCenter.
Der Clou dabei: Ein Benutzer legt ein Content Library-Objekt vom Typ local an und veröffentlicht dieses für den Internet-Zugriff via HTTPS (published).
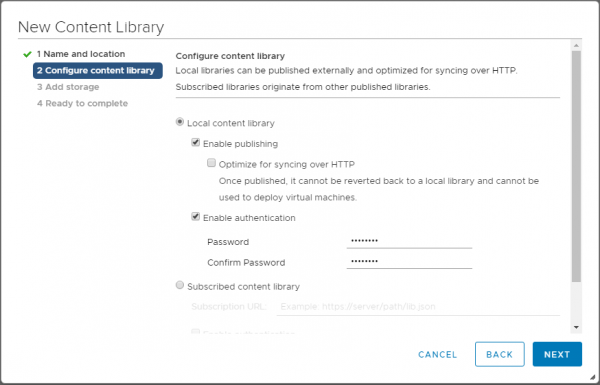
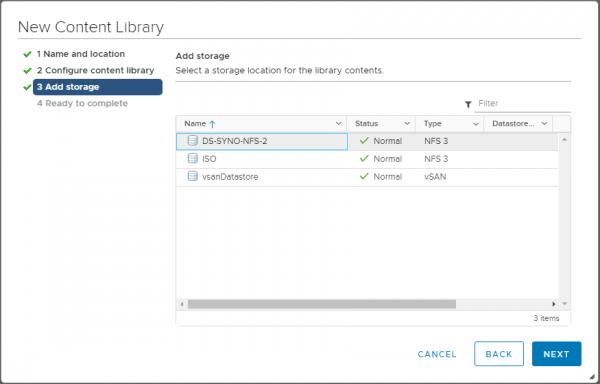
Optional kann der Zugriff auf eine Content Library mit einem Passwort geschützt werden, womit auch der Sicherheitsaspekt der oben genannten drei Stufen erfüllt ist. Im nächsten Schritt muss man das logische Content Library Objekt an ein Speicher-Backend binden, hier in Form von Datastores.
Die Veröffentlichungs-URL sieht man, wenn man danach in die Summary-Ansicht des fertig erstellten neuen Content-Library-Objekts wechselt. Diese kann dann dem jeweils anderen Standort in irgendeiner Form übermittelt werden, etwa durch eine verschlüsselte E-Mail.

Die Gegenseite kann dann mit Hilfe der URL ebenfalls ein eigenes Content-Library-Objekt, allerdings von Typ abonniert (subscribed) anlegen, wobei der Inhalt dann über das Internet (ggf. auch automatisch) synchronisiert wird.

Die besondere Speichereffizienz ergibt sich dadurch, dass ein Subscriber den synchronisierten Inhalt zwar in seiner Content Library sieht, dieser aber nicht notwendigerweise sofort in seinem Speicher-Backend abgelegt wird. Voraussetzung dafür ist, dass er beim Abonnieren die Option zur Speicher-Effizienz Download Content => when needed wählt.
Insgesamt gewährleistet das Publisher/Subscriber-Modell mit der eingebauten Synchronisation die Konsistenz der Inhalte, egal ob diese sofort oder nur bei Bedarf lokal heruntergeladen werden.
Verändert beispielweise eine Partei ein Objekt, dann tut sie das mittels Zugriff auf die Inhalte ihres eigenen logischen Content-Library-Objekts und nicht durch direktes Anfassen von Objekten im Datastore.
Die Gegenseite bekommt dann das geänderte Objekt (beispielsweise OVF) beim nächsten Zugriff auf sein Content-Library-Objekt bei aktivierter Funktion Download Content when needed automatisch. Wenn Inhalte dagegen bereits beim Erstellen der Content Library abgeglichen werden, erfolgt dies durch einen Klick auf den Synchronize-Befehl.