
Bei der Fehlersuche in komplexen IT-Infrastrukturen muss man sich unabhängig von Art, Tools-Chain und Hersteller eine stringente Methodik angewöhnen, um sich nicht zu verzetteln. Dazu zählen Top-Down- und Bottom-Up-Analysen. Wie das in einer vSphere-Umgebung aussehen könnte, zeigt dieser Beitrag.
Nahezu alle IT-Infrastrukturen lassen sich in verschiedene Abstraktionsebenen zerlegen. Selbst wenn man sich nur auf einer davon bewegt, wie etwa dem zugrundeliegenden Netzwerk, lässt sich dieses in weitere Schichten aufteilen, deren Kenntnis im Rahmen des ISO/OSI-Modells auch bei der Fehlersuche hilft.
Beispiel für ein Netzwerkproblem
Ob man sich dabei am ISO/OSI-Modell mit seinen 7 Schichten oder dem Internet/DOD-Schichtenmodell mit 4 Ebenen orientiert, ist gar nicht so entscheidend. Wichtig ist aber in jedem Fall beurteilen zu können, ob bei der Ursachenforschung eine Top-Down-, Devide and Conquer- oder Bottom-Up-Analyse sinnvoller ist.
Reagiert beispielsweise ein Web-Server nicht auf Anfragen auf Port 443, lässt sich aber per Ping erreichen (ICMP-Protokoll), dann braucht man den Fehler in Kenntnis des OSI-Modells nicht im Layer-2, etwa bei der Switch-Konfiguration zu suchen.
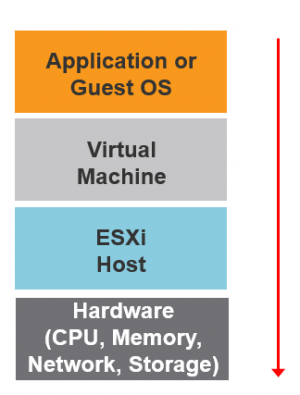
Schichten einer virtuellen Infrastruktur
Ähnlich verhält es sich in einer Virtualisierungsinfrastrukrur wie VMware vSphere. Hier können wir die vier funktionalen Ebenen physische Hardware, ESXi-Host, virtuelle Maschine und Anwendung bzw. Guest OS unterscheiden, wie folgende Abbildung zeigt.
Symptomatik
Die größte Schwierigkeit besteht nun darin, ein auftretendes Symptom einer Ursache zuzuordnen. Aufgrund der oben skizzierten Funktionsebenen lässt sich diese nämlich nicht auf dem ersten Blick eindeutig ausmachen. Daher ist eine stringente Methodologie unbedingt einzuhalten. Eine solche könnte so aussehen:
- Definieren des Problems
- Identifizieren der Ursache
- Lösung implementieren
Problem-Arten
Probleme wiederum lassen sich grob klassifizieren. Typische Systemprobleme sind etwa
- Konfigurationsfehler
- Ressourcen-Engpässe
- Software-Bugs
- Defekte Hardware
- Netzwerk-Attacken
Systemprobleme können sich auf zahlreiche Aspekte auswirken, wie die Verwendbarkeit, Korrektheit, Zuverlässigkeit oder die Performance. Dabei ist es aber leider häufig auf dem ersten Blick so, dass die Symptome das Problem selbst zu sein scheinen. Daher ist das Sammeln von Symptomen immer der erste Schritt zur Problembehandlung.
Dabei ist zu beachten
- Eine einzige Ursache wird von den Benutzern möglicherweise in Form mehrerer Symptome gemeldet.
- Die Unterscheidung zwischen Symptomen und den Hauptursache eines Problems ist oft nicht einfach, aber zwingend erforderlich.